
Dezentraler Cloudspeicher – Performant, sicher und preiswert?

Oder auch: Das Storj-Network in a Nutshell.
Die Welt spricht immer häufiger von “Distributed”-Services, also verteilten Services. Vor allem bei (kritischer) Infrastruktur oder CDN sind IaaS, Saas und Co auf der Überholspur.
Und das nicht ohne Grund: Dezentralisierung verspricht nicht nur schnelle und preiswerte Skalierbarkeit, sondern auch größere Ausfallsicherheit.
Aber wieso geht man beim Speichern von Daten oft genau in die andere Richtung? Und wieso sind zentrale Rechenzentren nicht nur ineffizient, sondern auch eine Achillesverse?
“Die Cloud” ist unter dem Strich nämlich wesentlich zentralisierter als man zunächst denkt.
Wir schauen uns in diesem Artikel einen völlig neuen Ansatz für die Speicherung – auch geschäftskritischer und großer – Datenmengen an. Einen dezentralen Ansatz der gleichzeitig mehr Nachhaltigkeit, hohe Performance sowie verbesserte Datensicherheit verspricht.
Status Quo: Cloud und zentrale Rechenzentren
Die Cloud hat in den letzten Jahren das zentrale IT-Modell für Unternehmen, Behörden und Privatnutzer geprägt. Die Nutzung von zentralisierten Rechenzentren dominiert weiterhin die IT-Infrastruktur weltweit. Lokale, kleine Rechenzentren, oder Storage-Infrastruktur sind in die Cloud ausgelagert worden, weil Skalierung kostengünstiger und einfacher möglich ist und die Verwaltung und Administration zentral gemanagt werden kann.
Die großen Cloud-Anbieter (AWS, Microsoft Azure, Google Cloud, IBM Cloud) betreiben weltweit zentrale Rechenzentren, die Nutzern virtuelle Server, Speicher und Anwendungen bereitstellen.
Ohne diese großen Unternehmen, die gewissermaßen das Rückgrat der Digitalisierung der Welt bilden, wäre moderne IT aktuell nicht denkbar.
Nachteile zentraler Rechenzentren
Aber zentrale Datenzentren haben auch gravierende Nachteile.
- Datenhoheit & Datenschutz: Die Daten werden oft über native Clients des Cloud-Unternehmens oder aber ohne zusätzliche Verschlüsselung gespeichert. In diesem Fall ist die Kontrolle über die Daten – insbesondere bei in den USA ansässigen Unternehmen, wie es bei den Big Playern in der Regel der Fall ist – fraglich.
- Regulierung und Geopolitik: Ein Rechenzentrum steht physisch an einem Ort. In einer Stadt, einem Land, einem Kontinent. Es lässt sich nicht einfach verschieben. Es unterliegt damit immer der jeweiligen Regulierung und Rechtsprechung des jeweiligen Landes. Das kann zu Problemen führen, wenn andere Regionen (das Beispiel Europa mit seinen vergleichsweise strikten Datenschutzanforderungen ist hier ein gutes Beispiel) Zertifizierungen fordern oder bestimmte Anforderungen an Rechenzentren stellen. Zudem geht mit der physischen Lage in einem Staat und dem entsprechenden Hoheitsrecht immer auch einher, dass – sofern nicht noch einmal vom Kunden verschlüsselt worden – das Einsehen oder die Herausgabe von Daten an Regierungsstellen erzwungen werden kann.
- Energieverbrauch und Nachhaltigkeit: Immer mehr Rechenzentren haben sich Nachhaltigkeit, Energieeffizienz und Umweltfreundlichkeit auf die Fahnen geschrieben. Und dass es erhebliche Anstrengungen für effiziente Serverhardware, effiziente Kühlungssysteme und die weitere Nutzung von Wärme gibt, steht ausser Frage. Trotzdem verbrauchen Rechenzentren enorme Mengen an Energie und die Abwärme verpufft viel zu häufig einfach so in die Umwelt. Für den enormen Energiebedarf und die notwendigen Anschlüsse an das (globale) Breitbandnetz sind zudem umfangreiche Arbeiten an der Infrastruktur notwendig.
Und ein Nachteil bleibt grundsätzlich bestehen: Die bereitgehaltenen Server laufen nur zu einem Zweck und sind oft nur zu einem Bruchteil ausgelastet. - Sicherheitsrisiken: Zentrale Datenzentren gleichen einem Hochsicherheitsgefängnis. Und das nicht ohne Grund, schließlich ist ein zentral gespeicherter Datenschatz ein lohnendes Ziel sowohl für physische Einbrüche und/oder Sabotage, als auch für Hackerangriffe.
- Kosten: Zunächst erscheint der Umzug in die Cloud kostengünstiger – und das ist sie in der Regel auch. Zumindest im Vergleich zu lokaler, selbst betriebener IT- und Storageinfrastruktur. Die mögliche Skalierung kann aber auch schnell zu einer Kostenexplosion führen – vor allem für Anwendungen, die viel Storage benötigen.
- Lokale Vorfälle: In der Cloud gespeicherte Daten liegen, wenn keine spezifische Konfiguration vorliegt, die zusätzliche Kosten nach sich zieht, in der Regel in einem Rechenzentrum. Dies kann bei lokal begrenzten Krisensituationen wie politischen Spannungen oder (Natur-)Katastrophen zu temporäre Nichterreichbarkeit, oder sogar zu Datenverlust führen.
Der Ansatz: Verwendung ungenutzter Ressourcen, dezentrale Datenspeicherung
Wie kann man nun diesen Problemen begegnen? Ein naheliegender Ansatz ist Dezentralisierung und Akquise ungenutzter Ressourcen. Heruntergebrochen also ein dezentrales Speichernetzwerk mit vielen kleinen “Rechenzentren”, in denen die Hardware aber nicht ungenutzt läuft, nur um vielleicht irgendwann einmal gebraucht zu werden, sondern in denen ohnehin Hardware läuft, die aber Ressourcen übrig hat.
Spannend: Dieses Konzept lässt sich natürlich nicht für heimische Computer oder Privatanwender nutzen, sondern auch auf bestehende, klassische Rechenzentren anwenden – und so nicht genutzte Ressourcen nutzen.
Was ist Storj?
Storj ist eine dezentrale Cloud-Speicherplattform, die Blockchain-Technologie und Verschlüsselung nutzt, um eine sichere und kosteneffiziente Alternative zu traditionellen Cloud-Diensten wie AWS, Google Drive oder Backblaze anzubieten.
Storj stellt dabei sog. Objectstorage zur Verfügung und ist ein “S3”-Drop-In-Replacement.
Tipp: Anders als in vielen Stellen im Netz zu lesen, hat die Datenspeicherung an sich bei STORJ nichts mit einer Blockchain zutun. Es wird für die Personen, die Speicher zur Verfügung stellen, lediglich die Bezahlung über den “Storj-Token”, einen ERC20-Token auf der Ethereum Blockchain, realisiert.
Im Kern geht es darum, Personen, die Cloud-Speicher benötigen, mit denen zu vernetzen, die ungenutzten Speicherplatz auf ihrer Festplatte anbieten möchten. Also Anbieter von Speicher und Nutzer/Nachfrager von Speicher. Im Kerngedanken ein guter fit. Jetzt stellt sich nur die Frage, ob das global verteilt zu konkurrenzfähigen Preisen und mit überschaubarem Overhead und annehmbarer Latenz möglich ist? Die Antwort gibt es im weiteren Verlauf des Artikels.
Das Projekt existiert seit 2018 in dieser Form und wird aktiv weiterentwickelt, der Code ist OpenSource, das Projekt kann man auf GitHub verfolgen.
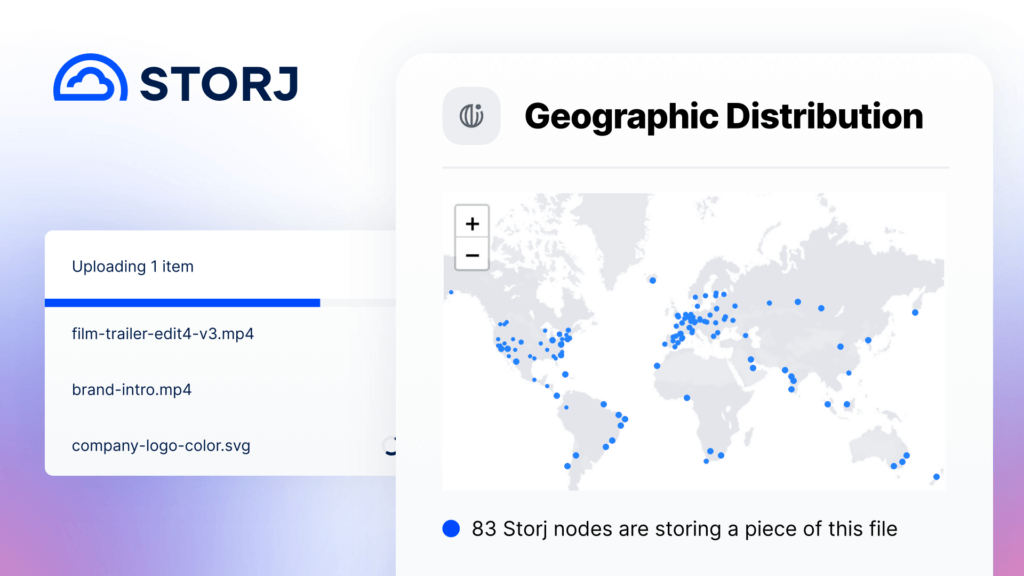
Bild 1: Geographische Verteilung von Datenblöcken.
Wie funktioniert das in der Theorie?
Man kann sich das Ganze wie ein Netzwerk aus tausenden einzelner Knoten vorstellen, die global über alle Kontinente verteilt sind. Jeder dieser Knoten stellt dem Netzwerk eine gewisse Menge an Speicherplatz zur Verfügung.
Wenn nun ein Anwender eine Datei hochlädt, wird diese zunächst verschlüsselt und in viele kleine Blöcke aufgeteilt (dies passiert gatewayseitig). Diese Blöcke werden nun global auf verschiedene Nodes verteilt. Die Blockgröße ist dabei so klein gewählt, dass mit Hilfe eines Algorithmus sichergestellt wird, dass das gesamte File auch beim Verlust bzw. der Nichtverfügbarkeit einzelner Nodes noch wiederherstellbar ist.
Dafür wird gleichzeitig eine Redundanz geschaffen, indem die Datenstücke auf mehrere Nodes repliziert werden.
Security, Endurance, Availability, Privacy – diese vier essentiellen Faktoren für Cloudspeicher gilt es unter einen Hut zu bekommen.
Dadurch wird in der Theorie nicht nur Privacy (Durch die Verschlüsselung), sondern auch Datenverfügbarkeit (Availability) und Sicherheit der Daten erreicht. Um die langfristige Verfügbarkeit der Daten (Endurance) zu gewährleisten, gibt es eine Art “Telefonbuch” (Satellite), in dem vermerkt ist, welches Datenstück auf welchem Node gespeichert ist. Wenn nun ein Node offline geht (und da es sich hier in der Regel um private Betreiber handelt, kommt das durchaus vor), wird vermerkt, dass eine Replikation weniger von einem Datenstück verfügbar ist. Wird ein kritischer Wert unterschritten, wird ein erneuter Replikationsprozess gestartet um wieder eine ausreichende Redundanz zu erreichen.
Ein Upload einer Datei ins STORJ-Netzwerk durchläuft also kurz und knapp folgende drei Schritte:
Sharding & Verschlüsselung
- Die Datei wird in viele kleine Teile (Shards) zerlegt.
- Jedes dieser Teile wird Ende-zu-Ende verschlüsselt.
Erasure Coding (Fehlertoleranz)
- Um Datenverluste durch ausgefallene Nodes zu verhindern, werden zusätzliche Datenblöcke durch Erasure Coding generiert.
- Diese Technik ermöglicht es, Daten selbst dann wiederherzustellen, wenn einige Speicher-Nodes offline sind.
Verteilung im Netzwerk
Durch diese Redundanz kann das Storj-Netzwerk sicherstellen, dass die Daten jederzeit abrufbar sind. Die verschlüsselten Fragmente werden auf mehrere Nodes verteilt (typischerweise 80 Nodes pro Datei).
Der Dreh und Angelpunkt: Der Expansion Factor
Aus den Herausforderungen der verteilten Datenstücke und der Speicherung auf grundsätzlich nicht vertrauenswürdigen Nodes – diese können jederzeit ausfallen und offline gehen – ergibt sich die oben genannte Notwendigkeit der Verschlüsselung und der Redundanz. Diese wiederum führt dazu, das je gespeicherter Dateneinheit, mehr Dateneinheiten im gesamten Netzwerk belegt werden müssen.
Man spricht dabei vom sog. Expansion-Factor:
Der typische Expansion Factor bei Storj beträgt ca. 2,7x.
Das heißt: Für 1 GB an Nutzerdaten werden etwa 2,7 GB Speicher im Netzwerk belegt.
Dieser Wert ergibt sich aus dem Erasure Coding Schema (z. B. 29/80 Konfiguration), das sicherstellt, dass Dateien selbst dann wiederhergestellt werden können, wenn ein Teil des Netzwerks ausfällt.
Erase Coding, Expansion Factor, Nodes, auf deren Verfügbarkeit man sich nicht verlassen kann. Das klingt alles sehr kompliziert und risikobehaftet, oder?
Nein, nicht unbedingt. Natürlich ist die Verteilung und Sicherstellung der Datenintegrität und -Verfügbarkeit auf einem System mit Nodes, die jederzeit verschinden können, einen zusätzliche Herausforderung. Aber diese Herausforderung lässt sich mathematisch ergründen und lösen, sodass man statistisch zu einer unglaublichen Datensicherheit von weit über 99,9999999% (!) kommt – das ist mehr, als bei herkömmlichen Rechenzentren und Diensten wie AWS und Co.
Erase Encoding ist auch in keinster Weise eine neue Technologie, es kommt in verschiedensten etablierten verteilten Systemen wie insbesondere verteilten Datenbanken oder RAIDs zum Einsatz.
Es sorgt dafür, dass Daten auch bei Verlust einzelner Teile wiederhergestellt werden können, ohne dass komplette Duplikate gespeichert werden müssen (wie bei klassischer Replikation).
Exkurs: Erase Coding im Detail
Für Erase Coding sind drei Paramater wichtig:
k = Anzahl der Datenblöcke
r = Anzahl der Redundanzblöcke
n = Gesamtanzahl der Blöcke
Dabei gilt logischerweise:
n = k + r
Also die Gesamtanzahl der Blöcke (Der gesamt belegte Speicher) ist die Anzahl der ursprünglichen Datenblöcke (Größe der gespeicherten Daten) plus die Anzahl der zu Redundanzzwecken als “Overhead” gespeicherten Datenblöcke.
Der Redundanzfaktor
Daraus lässt sich nun die Erasure Coding Rate (Redundanzfaktor) berechnen:
n/k = Redundanzfaktor
Der Redundanzfaktor zeigt dabei das Verhältnis der ursprünglichen Datenmenge zur real gespeicherten Datenmenge. Also der Faktor, um den der Speicherverbrauch durch Redundanz zunimmt. Die Interpretation des Redundanzfaktors ist damit auch eindeutig: Werte nahe 1 sind sehr effizient was die Speicherplatznutzung angeht, aber auch unsicher. Höhere Werte erhöhen die Sicherheit, aber gleichzeitig auch den benötigten realen Speicherplatz.
Am Beispiel von Storj ist der Redundanzfaktor = der Expansionfaktor.
Die Fehlertoleranz
Die Fehlertoleranz beschreibt den tolerierbaren Datenverlust, der wieder ausgeglichen werden kann. Also: Wie viele Daten dürfen verloren gehen, bis es zum Totalverlust kommt?
Die Fehlertoleranz errechnet sich aus:
n-k = Fehlertoleranz
Ein kurzer Vergleich zu klassischer Replikation und das Storj-Beispiel
| Merkmal | Erasure Coding (29/80 Schema) | Klassische Replikation (3 Kopien) |
|---|---|---|
| Speicherverbrauch pro 1 GB Nutzdaten | 2,7 GB | 3 GB |
| Datensicherheit | Sehr hoch (99,9999999%) | Hoch (99,999999%) |
| Maximal tolerierbarer Datenverlust | Bis zu 51 von 80 Blöcken | Bis zu 2 von 3 Kopien |
| Effizienz (Speicher vs. Sicherheit) | Hohe Effizienz (weniger Speicherverbrauch) | Weniger effizient (mehr Speicherverbrauch) |
| Rekonstruktionsmöglichkeit bei Ausfall | Ja, solange mindestens 29 Blöcke vorhanden sind | Ja, solange mindestens 1 vollständige Kopie vorhanden ist |
| Wiederherstellungsgeschwindigkeit | Schnell (Daten werden aus verteilten Blöcken rekonstruiert) | Langsamer (gesamte Kopien müssen neu geladen werden) |
Wir sehen also, Erase Coding ist ein etablierter, verlässlicher und vergleichsweise effizienter Ansatz zur Speicherung von Daten in verteilten Systemen.
Weitere wichtige Begriffe und Definitionen, die du im Zusammenhang mit STORJ kennen solltest
Schnell, schneller, STORJ?
Durch die große Distribution der Datenstücke ergibt sich in der Theorie ein weiterer großer Vorteil: Parallelisierung. Dadurch, dass nicht ein großes Datenpaket von A nach B geladen werden muss – und damit die Bandbreite der empfangenden Stelle, also beispielsweise des Rechenzentrums ein limitierender Faktor ist, sondern, dass die Datei in viele kleine Datenteile gesplittet ist, können viele Verbindungen parallel aufgebaut und die einzelnen Datenblöcke zeitgleich geladen werden. So lässt sich die Bandbreite der verschiedenen Nodes akkumulieren. In der Praxis ist dadurch zumeist die Sendende Instanz der Flaschenhals.
Diese Parallelisierung funktioniert nicht nur beim Upload, sondern auch beim Download von Daten.
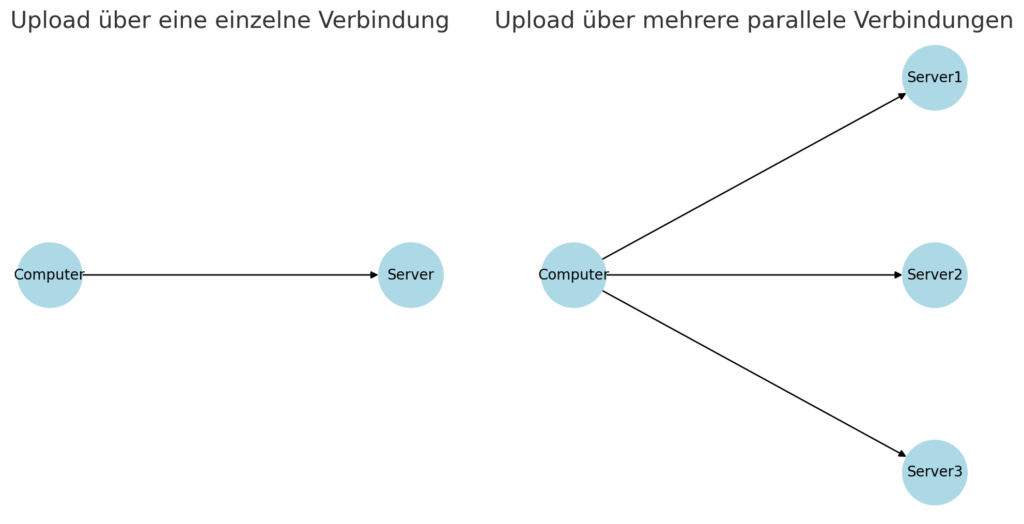
Bild 2: Schematische Darstellung eines parallelisierten Uploads.
Probleme mit der Latenz?
Ein Nachteil von Storj ist die Latenz. Das liegt in der Architektur des Netzwerks.
Da die Daten häufig auf “Heimcomputern” privater Anwender liegen, sind die einzelnen Nodes auch nur über heimische Internetverbindungen angebunden, das spielt bei der Bandbreite durch Akkumulation dieser keine Rolle. Die Latenz lässt sich aber nicht durch das Akkumulieren verschiedener Verbindungen senken – im Gegenteil.
Und Heimverbindungen haben in der Regel höhere Latenzen als Anbindungen von Rechenzentren und sind shared Medien. Zudem muss die Datei zunächst geshardet (gesplitted) werden.
Auch das Routing ist nicht beeinflussbar und erhöht in der Regel die Latenz.
Das ist von Nachteil für Dienste, bei denen die Latenz wichtig ist, beispielsweise Echtzeit-Anwendungen oder Datenbanken.
Für den primär vorgesehenen Einsatz von Storj als S3-Replacement für Massenspeicher, Streamingdienste (Abruf großer Dateien) sowie Backup und Archivierung spielt eine leicht erhöhte Latenz keine Rolle.
Schauen wir uns Werte aus der Praxis an:
- Zentrale Clouds (AWS, Google, Azure): < 50 ms
- Storj (dezentrales Netzwerk): 100–500 ms (variiert je nach Standort & Netzwerk)
Die Krux mit Zertifizierungen
Storj ist ein dezentralisiertes Storagenetzwerk. Und ist damit grundlegend anders aufgebaut, als zentrale Anbieter. Diese Dezentralität ist etwas Neues und in den bestehenden Zertifizierungen nicht berücksichtigt.
Während zentrale Anbieter industrielle Zertifizierungen (ISO, SOC, GDPR, HIPAA, etc.) relativ einfach erhalten, gibt es bei Storj einige Herausforderungen in Bezug auf Zertifizierungen.
Für viele potentielle (industrielle) Kunden sind folgende Zertifikate für Cloudspeicher von Relevanz:
- ISO 27001 – Informationssicherheits-Managementsystem (ISMS)
- SOC 2 (Service Organization Control 2) – Sicherheit & Datenschutz für Unternehmen
- GDPR (DSGVO in der EU) – Datenschutz-Grundverordnung
- HIPAA (USA) – Schutz medizinischer Daten
- FedRAMP (USA) – Sicherheitsanforderungen für Regierungsdienste
Die größte wirtschaftliche Relevanz hat sicherlich eine SOC2-Zertifizierung.
Bei den Zertifizierungen steht ein dezentrales Storage-Netzwerk vermutlich vor den folgenden Problembereichen:
1. Keine zentrale Kontrolle über die Infrastruktur
Problem: Bei AWS & Co. sind die Server in kontrollierten Rechenzentren, wodurch Zertifizierungen einfacher sind. Storj hingegen nutzt weltweit verteilte Speicheranbieter (Nodes), von denen viele private Betreiber sind – das macht eine zentrale Zertifizierung schwierig.
Lösungsansatz: Durch Algorithmen (siehe Fehlerkorrektur) und Ende-zu-Ende-Verschlüsselung die Daten unabhängig von einzelnen Nodes machen und die Kontrolle über die Hardware obsolet machen.
2. Compliance mit Datenschutzgesetzen (GDPR, HIPAA, etc.)
Problem: Daten können in verschiedenen Ländern gespeichert werden, was problematisch für Vorschriften wie GDPR (EU) oder HIPAA (USA) sein kann.
Lösungsansatz: Storj verschlüsselt alle Daten Ende-zu-Ende, sodass kein Node-Betreiber Zugriff auf die Inhalte hat.
Aber: Manche Regularien verlangen, dass Daten nur in bestimmten Regionen gespeichert werden – das ist in einem global verteilten Netzwerk schwer zu garantieren.
Lösungsansatz: Nutzung von Geofencing-Methoden, um sicherzustellen, dass z.B. Daten von Kunde XY nur in bestimmten geographischen Regionen gespeichert werden. Das funktioniert auch soweit näherungsweise und wurde bereits in der Praxis ausgetestet: Als Russland 2022 in die Ukraine einmarschiert ist, wurde mittels Geofencing eingerichtet, dass Nodes in Russland keine neuen Daten mehr erhalten. Der Hintergrund ist gewesen, dass zeitweise eine Abkopplung Russlands vom Internet im Raum stand. In diesem Fall wären alle Nodes aus einer Region schlagartig offline gewesen. Selbst in diesem Fall wären alle Daten sicher gewesen (Siehe: Erase Coding), es wäre aber zu vielen neuen Replizierungen gekommen. Um die Auswirkungen so gering wie möglich zu halten, entschloss man sich, neue Daten zunächst auf Nodes ausserhalb Russlands zu verteilen.
Trotzdem kann es hier keine 100%ige Sicherheit geben, beispielsweise könnten die Betreiber von Storagenodes potentielles Geofencing anhand von VPN-Verbindungen umgehen.
3. Auditierbarkeit & Transparenz (SOC 2, ISO 27001)
Problem: Zertifizierungen wie SOC 2 oder ISO 27001 erfordern, dass Unternehmen ihre Sicherheitskontrollen und Prozesse nachweisen können.
Storj kann nicht garantieren, dass jeder Node-Betreiber strenge Sicherheitsmaßnahmen einhält, da es sich um private Speicheranbieter handelt. Unternehmen, die regulierte Daten speichern müssen, können Probleme haben, Storj zu nutzen.
Lösungsansatz: Langfristig muss in die Zertifizierungen aufgenommen werden, wenn diverse Sicherheitsmaßnahmen aufgrund einer zugrunde liegenden Verschlüsselung der Daten nicht erforderlich sind. Kurzfristig hilft ein Netzwerk aus bereits SOC-2-Zertifizierten Nodes (siehe “Storj Select”).
Sonderfall “Storj Select”
In jedem Fall scheint sich Storj aktuell noch etwas schwer mit beispielsweise einer SOC 2 – Zertifizierung zu tun.
Stand März 2025 hat man – speziell um eine SOC2 – Zertifizierung zu erhalten, ein sog. “Storj Select”-Network aufgesetzt. Im Prinzip handelt es sich dabei um ein parallel betriebenes Storj-Network, das zwar über die gleichen Satellites läuft, aber Daten nur auf ausgewählten Nodes speichert. Diese für “Storj-Select” zugelassenen Nodes müssen jeweils eine eigene SOC 2 Zertifizierung nachweisen. So hat das gesamte Storj-Select-Netzwerk für den Kunden dann auch die SOC-2-Verifizierung.
Für die Zukunft ist wohl auch eine SOC2-Zertifizierung für das Public-Network angestrebt, aber dort gibt es aufgrund der obigen Problematiken bzgl. Zertifizierungen aktuell (März 2025) noch keinen Zeitrahmen.
Die Kosten / Der Preisvergleich
Dezentralität und die Nutzung von bestehenden Ressourcen – schön und gut. Wenn ich nun aber meine neue Cloud-Storage-Lösung mit der Geschäftsführung oder dem Controlling in Einklang bringen möchte, zählt vor allem auch ein Argument: Der Preis.
Schauen wir uns mal das Pricing des Storj-S3-Storage an:
- Speichergebühren: $0,004 pro GB/Monat -> 4$ pro TB / Monat
- Downloadgebühren: $0,007 pro GB -> pro TB Downloadvolumen 7$
- Segment Fee: $0,0000088 pro Segment/Monat (Daten werden in Segmente von bis zu 64 MB aufgeteilt. Jedes Segment, das über das Standardlimit hinausgeht, verursacht zusätzliche Kosten; Die Segment-Fee kommt in der Regel nur bei vielen kleinen Daten zum Tragen)
Wichtig zu wissen ist, dass die Abrechnung wie bei AWS und Co üblich nur entsprechend der realen Nutzung erfolgt. Wenn also z.B. nur 1 TB hochgeladen wird und kein Download erfolgt, werden auch nur die Speichergebühren abgerechnet.
Der aktuelle Preis ist hier zu finden: https://www.storj.io/pricing
Achtung, die folgenden Beispiele basieren auf dem Storj-Pricing-Calculator und sind auf einem Stand von Mai 2024.
Folgend ein kleiner Vergleich der Speicherkosten für das Speichern von 1PB Daten und ein über das Jahr verteilter Download von einem PB.
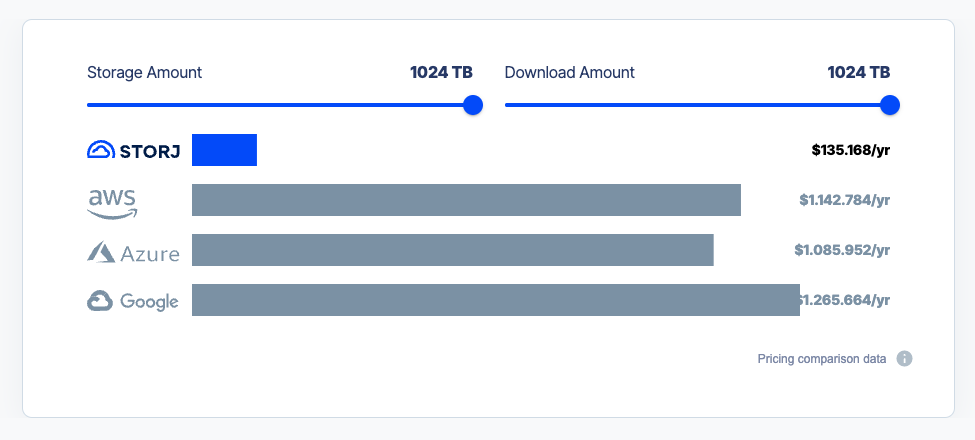
Bild 3: Vergleich der Storagekosten bei 1 PB Datenspeicher, der innerhalb eines Jahres einmal komplett wieder heruntergeladen wird (Quelle: https://www.storj.io/pricing).
Und so sieht der Vergleich für einen “Privatkunden” aus, der z.B. die eigene Fotosammlung oder das heimische NAS in der Cloud als Backup sichern möchte (3TB Speicherplatz, kein Download).
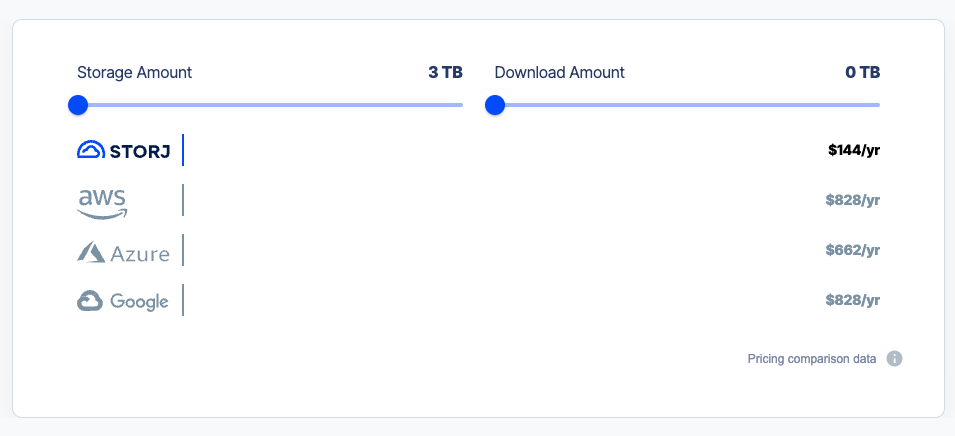
Bild 4: Zeigt ein klassisches Backup-Szenario für Heimanwender (3TB Speicher, kein Download). Quelle: https://www.storj.io/pricing.
Und wie funktioniert das in der Praxis?

Bild 5: Screenshot der Storj-DCS Oberfläche.
Im Prinzip wie in der Theorie 😉
Im Prinzip gibt es für dich, wenn du Storj als Storage-Backend nutzen möchtest, drei Wege.
1) Nutzung der Storj-DCS-Oberfläche.
2) Nutzung als S3-Storage-Backend in jeder Anwendung, die auch S3 unterstützt
3) Mit einem selbst aufgesetzten Single Tenant S3 Gateway (OpenSource)
Dezentraler Cloudspeicher (Storj) im Vergleich zu herkömmlichem S3-Storage
| Merkmal | Storj (Dezentral) | AWS S3 | Azure Blob Storage | Google Cloud Storage | Backblaze B2 | Wasabi Hot Storage | Cloudflare R2 |
|---|---|---|---|---|---|---|---|
| Architektur & Infrastruktur | Verteiltes Netzwerk mit unabhängigen Speicherknoten | Zentralisierte Rechenzentren weltweit | Zentralisierte Rechenzentren weltweit | Zentralisierte Google-Rechenzentren weltweit | Zentralisierte Rechenzentren (wenige Standorte) | Zentralisierte Rechenzentren (USA, EU, Asien) | Zentralisierte Rechenzentren, Edge-optimiert |
| Sicherheit & Datenschutz | Ende-zu-Ende-Verschlüsselung, kein zentraler Zugriff | Optional verschlüsselt, Anbieter kann Daten einsehen | Standard-Verschlüsselung, Zugriff durch Anbieter möglich | Standard-Verschlüsselung, Google kann Daten einsehen | Optionale Verschlüsselung, Anbieter hat Zugriff | Standard-Verschlüsselung, Anbieter hat Zugriff | Standard-Verschlüsselung, Anbieter kann Daten einsehen |
| Leistung & Latenz | Höhere Latenz, parallele Abrufe möglich | Geringe Latenz, optimierte Netzwerke | Geringe Latenz, hohe Skalierbarkeit | Sehr geringe Latenz, hohe Bandbreite | Mittlere Latenz, günstige Speicherlösung | Geringe Latenz, optimiert für große Dateien | Sehr geringe Latenz, optimiert für Edge-Computing |
| Kosten (pro TB/Monat) | $4 pro TB | $23 pro TB | $20–$25 pro TB | $20–$25 pro TB | $6 pro TB | $6 per TB | $15 pro TB |
| Egress-Gebühren (Datenabfluss) | $7 pro TB | $90–$120 pro TB | $85–$120 pro TB | $90–$120 pro TB | $10 pro TB | Keine Egress-Gebühren | Keine Egress-Gebühren |
| Verfügbarkeit & Redundanz | Erasure Coding (29/80), toleriert bis zu 51 von 80 Blöcken | 99,999999999% Verfügbarkeit (11 Nines) | 99,9999999% Verfügbarkeit (9 Nines) | 99,999999% Verfügbarkeit (8 Nines) | 99,99% Verfügbarkeit (4 Nines) | 99,99% Verfügbarkeit (4 Nines) | 99,999% Verfügbarkeit (5 Nines) |
| Compliance & Zertifizierungen | Keine offiziellen ISO, SOC2 oder HIPAA-Zertifizierungen | ISO 27001, SOC2, HIPAA, GDPR zertifiziert | ISO 27001, SOC2, HIPAA, GDPR zertifiziert | ISO 27001, SOC2, HIPAA, GDPR zertifiziert | ISO 27001, SOC2 zertifiziert | SOC2, HIPAA, GDPR zertifiziert | SOC2, ISO 27001 zertifiziert |
| Anwendungsfälle | Ideal für Backups, dezentrale & Web3-Projekte, günstige Speicherung | Optimal für Unternehmen, große Datenmengen, Web-APIs | Für Unternehmensanwendungen, hohe Compliance-Anforderungen | Ideal für KI, Big Data, Hochverfügbarkeitssysteme | Günstige Backup- und Archivierungslösung | Ideal für Backups, hohe Datenvolumen, Streaming | Optimal für Web-APIs, statische Webseiten, Edge-Speicher |
Anmerkung: Diese Tabelle wurde nach bestem Wissen und Gewissen zusammengestellt (Stand März 2025). Es können sich natürlich trotzdem Fehler oder aktualisierte Daten ergeben haben.
Zahlen, Daten, Fakten zum Storj-Network
Weitere Live-Statistiken zum Storj-Network findest du übrigens hier und hier.
Auf jeden Fall ein spannender Einblick 😉
Mein Fazit: Für welche Anwendungszwecke ist verteilter Speicher auf Basis von Storj geeignet – und für welche nicht?
Storj ist ideal für günstige Backups, Datenschutz-sensitive Anwendungen, dezentrale Web3-Projekte und große Dateiübertragungen. Es bietet hohe Sicherheit durch Verschlüsselung und verteilte Speicherung. Nicht geeignet ist Storj hingegen für Echtzeit-Datenbanken, Live-Streaming, Webhosting mit niedriger Latenz oder Unternehmen mit strengen Compliance-Anforderungen (z. B. ISO/SOC/HIPAA).
Kurz gesagt: Storj ist meiner Meinung nach eine sichere und kostengünstige Alternative für langfristige Speicherung, aber nicht die beste Wahl für hochverfügbare oder latenzkritische Anwendungen.
Der Ansatz, bereits existierende Hardware zu verwenden, klingt für mich durchaus nachhaltig. Es gibt sogar eine Webseite, die eine potentielle CO2-Einsparung aufführt.
Ich probiere Storj aktuell aus und lasse mein NAS in das Storj-Network backupen.
Durch die S3-Kompatibilität konnte ich ganz einfach meine Storj-Zugangsdaten in der Synology-Backup-Anwendung (Hyperbackup) hinterlegen. Bisher funktioniert das reibungslos.
Du findest das Thema spannend, hast Fragen, Anmerkungen oder einfach Diskussionsbedarf?
Dann lass uns in den Kommentaren darüber sprechen.
Quellen:
- https://static.storj.io/storjv3.pdf
Rückmeldungen